


 In-depth articles, series and guides
In-depth articles, series and guides
 Making AI Work
Making AI Work
Part of The Making AI Work Series
Artificial Intelligence has been the poster child of tech these last few years.
With tools like ChatGPT, Claude, and Perplexity gaining adoption and people becoming more interested in how AI can improve their lives, AI has become a hard-to-ignore technology.
But many of us barely know how these AI tools function, which leads to:
- Confusion on how and where to use these tools in our daily workflows
- Fear of being replaced by these tools in the corporate world
- Complete dismissal of this new technology, categorising it as hype that would eventually die
While it's true that big tech companies are over-hyping and aggressively marketing these tools, they can genuinely ease some of our work and free our time if we know their capabilities and limitations and learn to use them to our advantage.
In Part I of the Making AI Work series, I'll clarify the ambiguity surrounding generative AI and show you where you can benefit from this technology and where it's best to leave it outside your workspace. I'll also give you real-life use cases to help you start thinking of ways you can incorporate AI into your daily workflows to ease your work.
Let's start by understanding:
How Generative AI works
ChatGPT, Claude, Gemini and most other AI tools run on engines called Large Language Models or LLMs.
You can think of LLMs as incredibly sophisticated versions of the autocomplete tool you've seen on your computer and phone all these years. LLMs can form answers and essays by constantly predicting the next word in sequence until the answer makes sense.
Technically, they predict and generate tokens, which might be a whole word or a broken-down version of one, but for simplicity, we'll identify them as individual words.
This analogy of being a “next-word predictor” dramatically simplifies how LLMs work because they involve complex math and layers of processing underneath that make this magic happen.
Your job won't likely require you to build an LLM from scratch, but understanding how LLMs work can help you use one effectively and recognise when it is not the best tool for the task.
In this article, we'll skip the math and other technicalities and instead understand how LLMs work through simple, real-world explanations:
When you ask a question or put in a request on a generative AI app, such as ChatGPT or Claude, the underlying LLM begins its work by identifying patterns in your query.
First, it scans your query from various angles simultaneously to understand the key ideas and the task it's assigned to do:

This process is called self-attention and works by leveraging multiple attention heads that each asses the query on specific criteria — the semantics, the structure of the prompt, and many more.
The LLM processes each word in the query and identifies its relation to every other word.
For example, in the sentence, “I locked my house when I went out”, the word “locked” is more closely related to the word “house” than the word “out”:

Forming such relations helps the LLM dissect your question or request, find inter-word connections and understand precisely what needs to be answered — much like a detective laying out facts to investigate a crime scene.
It also pays attention to the position of each word in the query, which can completely change the meaning of a sentence.
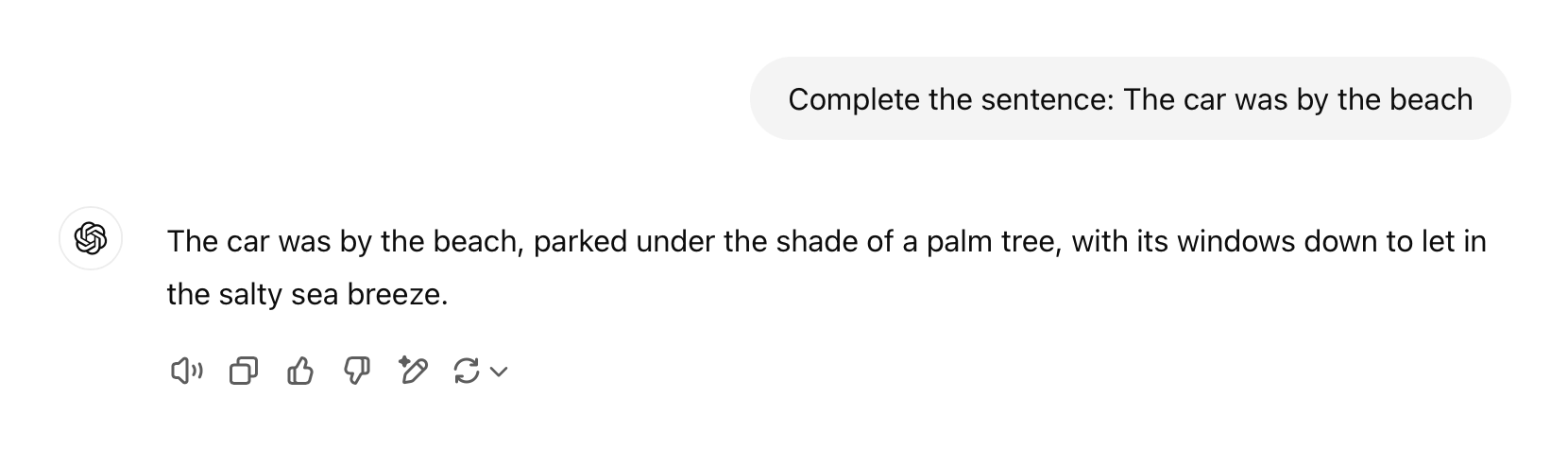
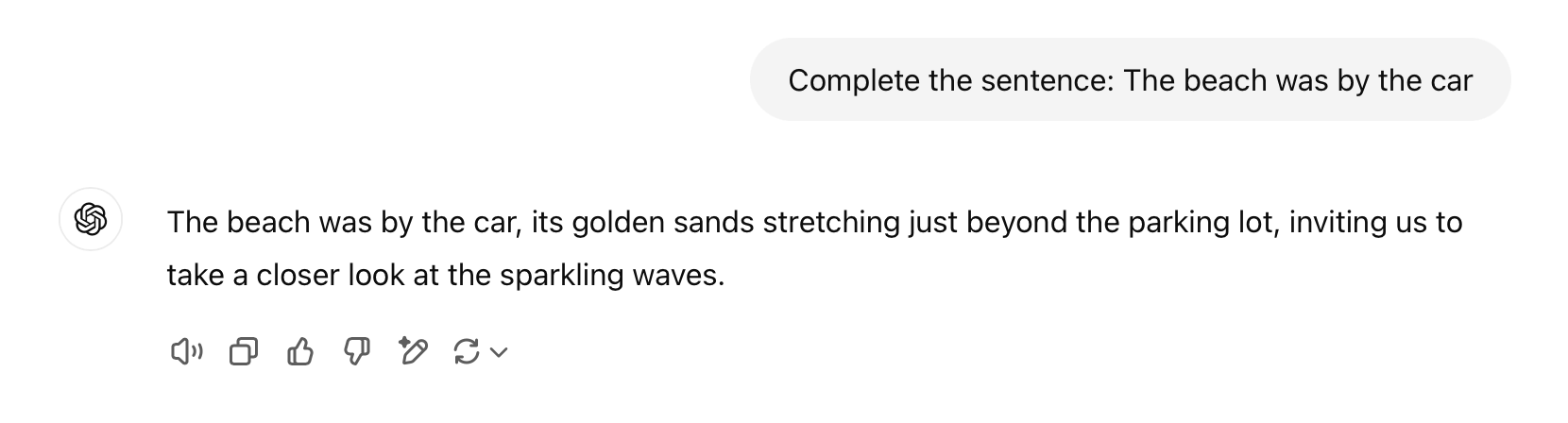
For example, “the car was by the beach” and “the beach was by the car” have the exact words in both sentences, but they mean different things because of where each word is placed in the sequence.
Therefore, if you ask ChatGPT to complete the sentence, “The car was by the beach”, it answers keeping the car as the subject:
And vice-versa for the other variation:
This process is called positional encoding and helps LLMs understand what we're trying to say.
The whole process is similar to how we comprehend a question before answering.
We read the question well, understand the context, and identify what and how we must answer to respond satisfactorily.
Once the LLM has deciphered the query, it starts leveraging what it has learned in its training and alignment stage to generate the first word in its answer.